Covariance and Correlation
While dealing with any ML project one spends most of the time in data preprocessing .Data pre-processing is nothing but playing with the features present in the dataset ,data cleaning,data transformation ,removing or imputing missing feature values etc. Feature engineering corresponds to developing new features based on current information .
It may happen that few features are related to each other be it directly or inversely .
Consider three cases:
- Let's say radius and circumference are features present in the dataset ,so we know that they are directly dependent .Here if radius increases ,perimeter also increases.

2. Let's say speed and time are features present in the dataset ,so we know that they are inversely proportional .Here if speed increases ,time required to cover a distance decreases.
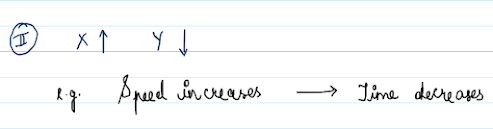
3. Let's say height and hair color are features present in the dataset ,so we know that there is no relation between the height of the person and the hair color of that person.
There are broadly two ways to measure dependance or statistical relationship between two features.
- Covariance
- Correlation
Covariance:
It tells about the statistical relationship between two features , and it is calculated by the formula.


1. Covariance is positive i.e. cov(X,Y) > 0 , implies that if X increases Y also increases
2. Covariance is nearly zero i.e. cov(X,Y) = 0 implies that X and Y are not statistically dependent
3. Covariance is negative i.e. cov(X,Y) < 0 implies that if X increases Y decreases
Demerit of Covariance is that, as it is not normalized so ,it depends on magnitude of variable and hence it is not that easy to interpret.
To overcome this demerit we use Correlation Coefficient which basically shows the strength of the linear relation
The sign of the covariance shows the tendency in the linear relationship between the variables.
1. Covariance is positive i.e. cov(X,Y) > 0 , implies that if X increases Y also increases
2. Covariance is nearly zero i.e. cov(X,Y) = 0 implies that X and Y are not statistically dependent
3. Covariance is negative i.e. cov(X,Y) < 0 implies that if X increases Y decreases
Demerit of Covariance is that, as it is not normalized so ,it depends on magnitude of variable and hence it is not that easy to interpret.
To overcome this demerit we use Correlation Coefficient which basically shows the strength of the linear relation
Correlation:
Statistically speaking it refers to degree to which two features are linearly related. It is synonymous with dependence. It can roughly be called as Normalized version of Covariance.
Several important Correlation Coefficient are given below
 If there is any sort of relationship between the variables ,we may end up getting the values of Pearson coefficient as positive ,negative or zero.It's value lies between -1 and 1
If there is any sort of relationship between the variables ,we may end up getting the values of Pearson coefficient as positive ,negative or zero.It's value lies between -1 and 1

It is sensitive only to a linear relationship between two variables .
Rather than finding statistical dependence between two variables alike in Pearson Coefficient Correlation, it focuses on finding statistical dependence between ranking of two variables
Here rank means relative position label of the observations within the variable:

Given height and width in a dataset we will create a new columns i.e. Rh (rank of height) and Rw (rank of width) and correspondingly write the rank of height as well as rank of width in descending order as shown in above figure.
Several important Correlation Coefficient are given below
I) Pearson Correlation Coefficient:
It assess linear relationship between variablesMathematically speaking it divides the covariance of X and Y by product of standard deviation of both variables
Credits: wikipedia
It is sensitive only to a linear relationship between two variables .
II) Spearson's rank Correlation Coefficient:
It assess monotonic relationship between variables
Rather than finding statistical dependence between two variables alike in Pearson Coefficient Correlation, it focuses on finding statistical dependence between ranking of two variables
Here rank means relative position label of the observations within the variable:

Given height and width in a dataset we will create a new columns i.e. Rh (rank of height) and Rw (rank of width) and correspondingly write the rank of height as well as rank of width in descending order as shown in above figure.
Now find the Pearson Coefficient Correlation between rank of this variables .


The sign of the Spearman correlation indicates the direction of association between X (the independent variable) and Y (the dependent variable). A Spearman correlation of zero indicates that there is no tendency for Y to either increase or decrease when X increases.

The Spearman correlation ( r) is less sensitive than the Pearson correlation (rho) to strong outliers that are in the tails of both samples. That is because Spearman deals with the value of its rank.


The Spearman correlation ( r) is less sensitive than the Pearson correlation (rho) to strong outliers that are in the tails of both samples. That is because Spearman deals with the value of its rank.

Correlation v/s Causation
If X is highly Correlated to Y that does not necessarily means that X causes Y.Lets say:
Not wearing mask is correlated with Covid infection but that does not mean that absence of mask has caused the Covid infection ,it's the corona virus that has caused the infection
Conclusion:
- Correlation is better measure of finding dependencies between variables than Covariance.
- Correlation is normalized version of Covariance.
- Spearson is more robust than Pearson's i.e. more sensitive to nonlinear relationships as well as outliers.
- Covariance lies between -infinite to +infinite .
- Correlation lies between +1 to -1 .


Very nicely explained.. keep it up buddy
ReplyDeleteSuperbly explained 👍👍👍Waiting for more such blogs
ReplyDeleteGood work man!
ReplyDeleteCome up with more blogs